这段时间主要是扑在算法上了,这些工程领域的知识有点遗忘了。所以趁着这次复习,复习下之前做过得项目。同时,正好当时,Redis 官方还没有集群方案,所以才有了之前的 Cache 集群方案,现在正好也看看 Redis 官方的方案。
Codis 方案
一张 Codis 官方给出的架构图:
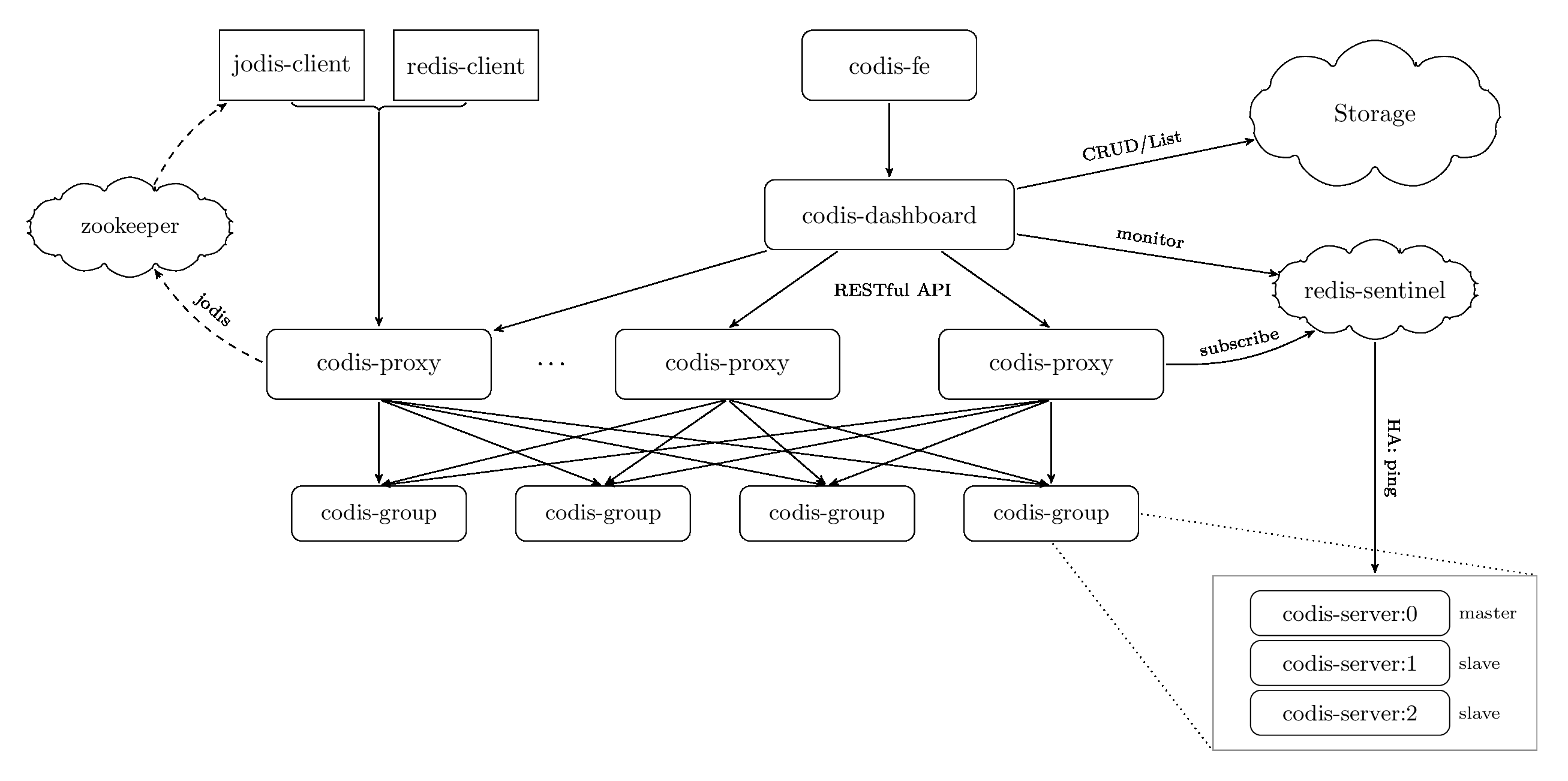
- 可以看到,它是采用了 proxy 的方式,和 Redis 官方给出的去中心化的思路不同,Proxy 是一种中心话的思路,将 Redis 仅仅作为存储引擎来使用。这一点其实比较符合组件化的原则,每一个组件只需要做一件事。同时,proxy 的方案,也非常利于简化代码的逻辑。
- Zookeeper 用来维护整个集群的 metadata 信息。相比较于去中心化的思路,中心话带来的就是一致性问题。比较简单的,在多个 proxy 中,如何维护同一个正确的 redis 集群信息。所以这个使用了 Zookeeper 来进行维护。也算是做到了 HA。
- 至于 proxy 中的分区算法,依旧是采用的一致性 Hash 算法。这个也算是在这种扩展性上的一个比较通用的处理手段。
- 记得我们当时讨论过,是否直接采用这个方案进行部署。但是,当时的负责人始终坚持自研,但是最后的方案也还是参考的 Codis 进行,不得不说是一个很没有意思的事情。
一致性 Hash
其实就是将一个一维线性的地址空间做成环状,收尾相接。
- 同时部署在上面的机器,都会握有一个 index,比如 1024 中的 256,512,768,1024 这四台机器。
- 当一个 key = 268 值传入时,就会找第一个接近的值,这里就是 512 号机器。
- 如果 key = 1025 那么,就会 key = key % 1024 从而映射到 256 上。
Zookeeper 如何进行一致性保证
为什么需要 Zookeeper,上文也说过了,就是保证 Proxy 能获取到最新且一致的集群信息。也就是一致性保证。
一致性保障,其实比较完善的解决方案也就是 Raft 和 Paxos 两个算法。这边 Zookeeper 则是使用的叫 Fastleader 的选举算法,在多实例的情况下,通过选举出来一个 master 进行决策,从而避免了多机同时处理导致的不一致。
Fastleader 算法:
先上一个算法流程图:

- 第一反应就是和,Raft 算法好像啊。
以上是 Raft 协议的一个状态转移图,可以看到,和 Zookeeper 的选举不同的是,他没有固定的 Observing 状态(一直默默参与数据同步,但是不参与投票)。而且,ZooKeeper 中,一旦 server 进入 leader 选举状态则该 follower 会关闭与 leader 之间的连接,从而旧 leader 无法发送复制数据的请求到新的 leader 上,从而避免了干扰。

具体可以看 图解zookeeper FastLeader选举算法。
至此,基本上说了第一个方案。
Twemproxy 方案
这个也是最早的一个集群管理方案了,更倾向于一个基本的 client 端的静态 sharding。而且他的介绍也很简单,就是提供一个轻量级的代理服务,主要是为了减少后端的连接数。。。所以不是很明白为什么很多人都会写博客说用它做集群会很麻烦。。他本来就不是为了复杂集群管理业务而设计的。。
Redis 官方方案
也是一个使用了一致性 Hash 算法的方案。不过他有意思的一点就是去中心化。主要的好处就是,加入 {A, B, C} 三台机器作为一个集群,那么,你连上任一一台机器,你的所有请求都会在 Redis 内部进行处理,而不会暴露在外面。不过坏处也是显而易见的。访问缓存,基本上都是大量的短连接。所以,这边做并不会减少这个问题的产生(Twemproxy)就是因为这个而产生的。
具体的算法实现:
A, B, C 三个节点,采用哈希槽 (hash slot) 的方式来分配 16384 个 slot ,三个节点分别承担的 slot 区间是:
- 节点 A 覆盖 0-5460;
- 节点 B 覆盖 5461-10922;
- 节点 C 覆盖 10923-16383.
获取数据:
- 如果存入一个值,按照redis cluster哈希槽的算法: CRC16(‘key’) % 16384 = 6782。 那么就会把这个key 的存储分配到 B 上了。同样,当我连接 (A, B, C) 任何一个节点想获取 ‘key’ 这个key时,也会这样的算法,然后内部跳转到B节点上获取数据
新增一个主节点 D,Redis 会从各个机器的前段,拿出一部分给 D:
- 节点 A 覆盖 1365 – 5460
- 节点 B 覆盖 6827 – 10922
- 节点 C 覆盖 12288 – 16383
- 节点 D 覆盖 0 – 1364, 5461 – 6826, 10923 – 12287
同样删除一个节点也是类似,移动完成后就可以删除这个节点了。
那么,HA 的保障则是有节点的 master-slave 来进行维护。
讲道理,这个方案真的复杂。多个节点需要维护同一个划分值,也是挺可怕的,去中心化的另一个意思就是每一个节点都是中心。也难怪官方憋了那么久才放出来。
以上就是这个项目的一些回顾,主要是前期工作的调研过程,顺便也算了解了下 Redis 的本身集群的设计思路。