故这样的,之前在 Leetcode 遇到一道题:『Edit Distance』, 当时做的时候并没有太多的思考,原因也很简单,不知道这道题的算法什么时候可以用得到。
直到,最近在看搜索引擎部分的算法,在处理用户的拼写异常的时候,比如,当用户搜索 『苏州大雪』的时候,怎么能进行纠错为『苏州大学』。
亦或者,在进行爬虫数据筛选的时候,比如在 B 站进行动漫数据抓取的时候,有很多的 UP 主会对动漫的名字做一定的修改,比如『(xx 字幕组)小林家的龙女仆』或者『小林家的龙女仆(高清)』。按照我之前的处理方式,还是很简单的 KV 存储,所以在计算弹幕和播放量的时候,并没有统计合并这样的数据。而从实际情况上来看的话,这两个的数据是应该统计在一起的。
所以,发现这个算法也是可以用的。而且,这个算法确实挺有意思。
using namespace std;
class Solution {
public:
int minDistance(string source, string target) {
int m = source.length(), n = target.length();
vector<vector<int> > DP(m + 1, vector<int> (n + 1, 0));
for (int i = 1; i <= m; i++)
DP[i][0] = i;
for (int j = 1; j <= n; j++)
DP[0][j] = j;
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
if (source[i - 1] == target[j - 1]) {
DP[i][j] = DP[i - 1][j - 1];
} else {
DP[i][j] = min(DP[i - 1][j - 1] + 1, min(DP[i][j - 1] + 1, DP[i - 1][j] + 1));
}
}
}
return DP[m][n];
}
}; 核心算法也就是这么一点,而且时间复杂度来看的话,也只有 O(n^2),相对于 B 站动漫的数据(万级别),也是可以接受的。 同时,考虑到简单的写法空间复杂度为 O(MN),不过实际使用中,只会使用到两排的数据,其实也可以对 DP 数组进行压缩。不过,并没有那么急切。
算法确实很有意思。
但是,业界上,还有其他挺多的有趣的算法。比如非常工程化的字典,规则等等。这些通常是基于实践结果,而后进行的统计算法。 算法的准确度通常也需要人工介入。
说了这么多,其实也只是停留在拼写异常的纠错上。并没有加入同义词替换。比如说:『笔记本 内存8G』 和『笔记本电脑 大内存』这样的 query 串的合并。有个很好的办法就是对其商品进行加 tag,然后对关键词进行分类,将其转换成不同的 tag,然后根据 tag 进行数据的筛选。
当然,如果再要引入业务上的排序,这些,就会出现这样的一个架构设计:

最后的纠错,其实还是落在了字典的充实度上。爬取 B 站的动漫名,这样的集合还是非常容易获得的。可以从对应的网站,比如『豆瓣』,『IMDB』 等电影评论网站上获得所有的动漫的名字,然后更具相似度进行分类。
就目前的可控使用的搜索三方库来看的话,比如说 Lucene,他也并没有提供这么一个搜索串纠错的功能。同时参考其他公司的架构实现:
蘑菇街:
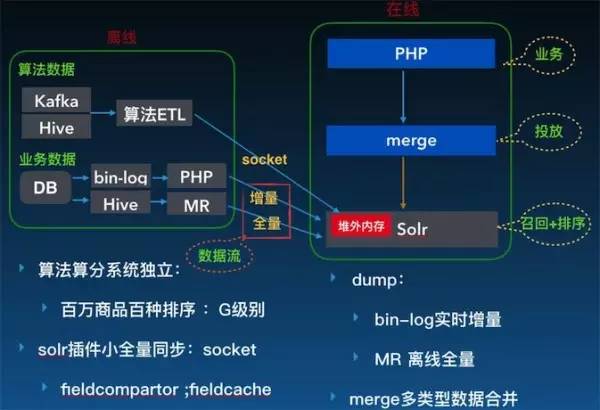
可以发现,很多的都是基于 Solr,或者 ELK。而对于 solr 而言,它提供了纠错的组件,比如,而仔细看下来,他的源码实现也是基于最短编辑路径的算法。
同时网上大量充斥着效果不好的言论,其实也很好理解。毕竟这个是基于文本匹配的算法。并没有做任何的优化。比如有 N 个名词的字典,词长度平均为 M,那么时间复杂度就可以达到 O(M*N^2) 这样一个恐怖的数据。所以会有各种定制化的纠错手段出现。同时,也会更具业务进行划分。
比如根据当前的地理位置,缩小字典库之类的。所以,那些个工程化很浓的解决手段,比如规则匹配,易错词表都有了用武之地。
同时,除了这些死算法之后,当下的热门机器学习似乎也是有参与其中,不过这一块的知识有待补充。
搜索这块,还是挺有意思的。